In CodeMirror 6 design docs you mentioned lazy rendering. I wonder if you tried implementing similar performance optimisations for ProseMirror.
What are the potential pitfalls if one attempted to do that? First thing that comes to mind is searching within the document (cmd+f), printing (cmd+p) and fast scrolling. I am very interested to hear how did you solve those problems in CodeMirror.
Nope. This is really complex to get right, even for flat text like in CodeMirror. ProseMirror is already complex for other reasons, so I intentionally shied away from adding another source of bloat and fragility.
Neither of those are solved. For search, you’ll want to provide our own custom dialog. For print, you should be able to use the beforeprint command to force-render the whole document, but we haven’t implemented that (I just filed an issue).
The main difficulty are with reacting to scrolling in such a way that the visible part of the document is always drawn, which requires knowing the height of everything, even the parts that you never rendered. In code editing, it is not uncommon to view multi-megabyte files (build artifacts, data sets), and this appears to be less common in rich text editing—but yes, if you try to edit a whole book as a single document in ProseMirror, you’ll probably notice a slowdown and a lot of memory used.
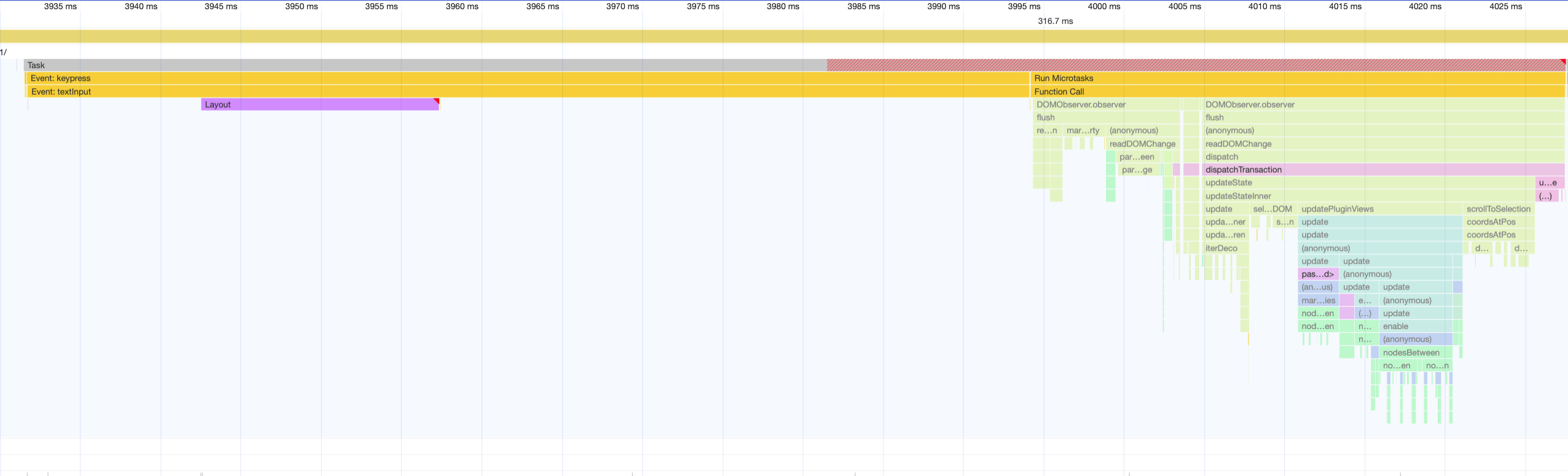
I just did some testing, and yes, it seemed to perform the same (if not a little worse, even) than the editor on prosemirror.net.
For posterity, I started a performance recording and made a small edit to a 7.5mb document. It took 96ms, with most of it in browser code, and only 33ms in prosemirror code it seems (if I’m reading this right).
In TipTap’s demo, although there is 200k words, this is somewhat of a cheap / gamed test imho, as the performance is dependent (much more sensitive) to number of nodes, not number of words. This demo would (theoretically?) perform the same / similar if there was a single character in each paragraph instead of very long paragraphs (at least for some in that demo.) A benchmark should really be focused on # of DOM nodes…
With one exception: it’s notable that native browser spellcheck is turned off with that attribute flag. This, in my experience, was causing severe performance degradation with large #'s of words, at least in chromium’s implementation of spellcheck but most probably with all implementations, which in TipTaps demo case is extra important since it’s word heavy and # of block/node light (relatively as there are some short quote paragraphs).
So a simple performance enhancement would be to turn off spell check when # of blocks is over X and inform the user clearly of this decision.
Finally, I’ve always been interested in a mature occlusion culling solution but @marijn clearly elucidates the handful of concerns therein. Pagination would feel clunkier and puts an even larger hamper on native browser search UX but there is room for a mature implementation there as well
This, in my experience, was causing severe performance degradation with large #'s of words, at least in chromium’s implementation of spellcheck.
I remember this as well, but I did some basic testing and didn’t notice a difference (macos). I wonder if chromium now runs that off the main thread or similar.
Finally, I’ve always been interested in a mature occlusion culling solution
I tried content-visibility: hidden, hoping it would help, but didn’t seem to have any effect. (it’s chromium only, and I’ve used it successfully before).