So, just to give a little context here, I’m working with something that emulates pages in an editor i’m making, and one of the biggest issues I’m having is maintaining the selection between pages. Currently the way it works is it calculates the height of the page and when it reaches some maximum height it’ll grab another node or two from the next page and then try to slice them by their lines. So, whatever fits stays and something that half fits gets sliced and moved to the next page. Unfortunately, cutting and moving nodes causes the selection to go to the start or end of some node and then you have to manually change it using whatever prosemirror feature you want to try to handle that with.
So what I was wondering is if there could be the potential addition of something to not copy or cut and then delete and insert. But, just move a range restricted to a particular depth (ex: depth >= 1) to a position and then behave like insert and maintain selection if it were contained in it. This is probably a pipedream, but I’ve spent like 3 weeks trying to do this now. I Figure, what the hell, I’ll ask. Even if there were a way to move nodes and keep the selection position relative to it. That’d be just as useful.
I’m not expecting a yes, but, It’d be nice to hear what your take might be. Or anyone else.
My apologies but, I was just looking through the reference manual and noticed Mappable. This might be the solution to my issue if I have a series of steps yes?
Hey, this sounds very interesting. A few years, when CSS Regions were a thing in Chrome, we had a version of our editor where it would divide the content into virtual “pages” that one could print out directly.
I thought we may be able to do something similar by basically using the same state on two views and move those views around so that the user always sees 1-2 pages and they appear to follow one-another.However, at the last ProseMirror meetup it sounded like this sounded useless to developers of other projects, so given that we weren’t likely to find collaborators for this, we dropped it for now.
The one thing I couldn’t figure out conceptually was how to deal with footnotes: If a footnote eats into the space used for the body text, then how do we figure out how much space there is available for the body text without rerendering 2-3 times? This was a challenge with PaginationJS/BookJS, and in combination with ProseMirror this seems really difficult to handle.
What I have works as far as pagination goes, The problem is the selection. I think I pretty much have that now. But, it sucks trying to deal with the caret moving all the time. Footnotes aren’t an issue, Just use a decoration and put it first on the page and use absolute positioning relative to the page. The problem with what I’m doing for the people I work for is that there’s no good way to calculate stuff based on CSS without rendering anyway. And I guess I’m obligated by my agreement not to say much about how I’m doing it. But what I Will say is that I have to prerender to figure out what will fit. I have a thing to calculate word wrapping and so on. It can paginate like 100 pages in approximately 1 second. But, Despite that, the real issue is selection and hopefully performance gains in Prosemirror later on. It’d be nice if PM itself supported pages. But, I guess we cant really expect that in the first place. There’s many issues between the browsers trying to emulate pagination at the node level. Just so anyone reading this knows. Edge is garbage. Just saying.
Hmm, I guess it’s difficult to say much without seeing the code. I guess that’s the flipside of you not being able to share much info. Interesting to know it works though.
Its by no means amazing or works enviously well and the synchronous state of things makes it a little laggy. But, I do my best to calculate when a page needs to be paged by calculating obvious things, which causes overhead when typing in exchange for less overhead when typing. yay.
The part that kinda makes it hard is if you have a lot of stuff where you want to reuse data that causes forced reflows, you can do that but, if you dont need the data everytime you’re causing forced reflows anyway. I’ve had the best catch-22’s ever working on this.
I see. We were also always just about quick enough for it to be acceptable. One obvious strategy is to note the exact width of how much each letter occupies. In theory that should let you be able to calculate everything without drawing anything. The problem is just that it’s really hard to get right unless you employ your own line-breaking code, and that is not really possible with ProseMirror.
On that note, thats what I am using. Constant number of characters per line, however, due to how our content can be formatted variably based on types of nodes and the order they appear, the space between nodes is variable. And therefore there would still be some overhead to calculate the space between nodes. It might still be possible. I might try it later to squeeze more processing speed out of it. The whole prerender costs a lot of time, I imagine I will have to at some point, It’s quite the job to make this all work I will say that.
The whole point of my prerender is to calculate the space between nodes. I can calculate the height of a particular node based on the previous obvious strategy you mentioned. Unfortunately, wordwrap is annoying… What I have does work right for now but, its not overriding anything from prosemirror, just using the css rules and trying to emulate that.
You could change your approach to move (delete and re-insert) the page node boundary rather than the content – that’d make mapping do the right thing.
But in general, encoding presentation-related things in the document model isn’t the ProseMirror way, and the recommended approach would be to have the user edit a non-paginated version of the document and do the pagination in a separate step.
If you have to have pages as nodes, you can still delete the end/start tokens between two pages to remove a boundary, and then insert them somewhere else to insert a boundary.
I don’t have a ready-made solution, and you might want to have manual page breaks in your document model, but I definitely wouldn’t put pages in the document model. You could show where the page breaks will end up in your editing interface if you want users to immediately see that, without actually modeling your document around them.
They are not <div>s, but ProseMirror document node boundaries. I.e. if your document is page("A") page("B") and the end of the first page is at document position 3, you can delete from 2 to 4 to remove the page boundary. Similarly, you can create a slice that has only a page boundary (with content page() page(), openStart=1 and openEnd=1) and insert that somewhere to create a new page boundary.
I’m not going to work out a full solution for you, I’m just saying I wouldn’t represent rendering-related information in the document itself.
I get what you mean - it seems backward. The trouble is that some users just cannot live without pages during text editing. We can all argue with our users – in the end we have to create the products they believe they need.
But I was thinking about your comments on this at the Berlin meeting. In our case, it may be worth to explore if the users could accept something like a horizontal line that is drawn across the page roughly every 300 words (or so). That should still give them a lot of the advantages pages used to give them (a way to visually divide the text into larger units), which should be a lot less costly for us. Not sure it will work for all end users, but it would be worth a try.
I wouldn’t expect you to do anything like that, I was just wondering what you were thinking since you must be thinking something to suggest breaks in the page without document model level node containers. Our pagination is very rule oriented so there may be no choice for us, but, if you think that moving the page break may be more efficient I can try that.
@marijn using NodeViews you could create pages and place the nodes into those pages. Is that a feasible idea or potentially hazardous to some of the functionality of prosemirror. Would require a lot of querying and moving dom nodes around i guess i’m just wondering if that is one of the possible solutions
@marijn Using just your advice on the current way we’re doing pages (in the model), we had ~1.35seconds to paginate an entire 120 page document where all the nodes are inserted into the first page and then running the paginate.
After your improvements, we went to 240ms under the same/similar conditions, although, I did some of my own improvements like how I calculate height trying to make use of more constants, etc.
I think it’s worth mentioning this is done entirely with split, join and setNodeType. Nothing else.
EDIT: I mean, this is not exactly what you said, but, when I looked at your api, I saw the split/join. That tends to help a lot with selection. So far selection handling is much easier AKA: Haven’t had to mess with it period so far.
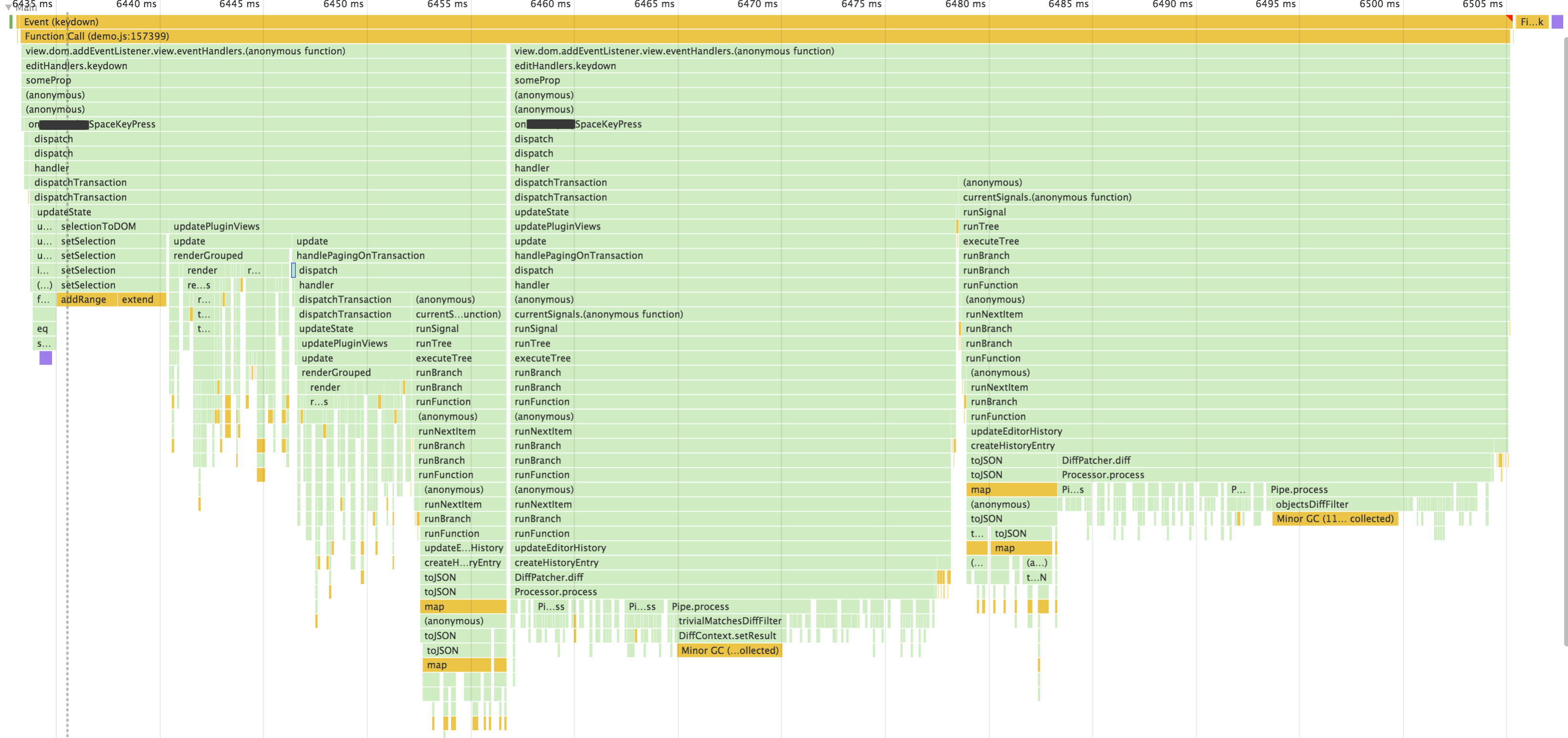
Sorry to bother you again @marijn but, I’m just wondering if you could give me your opinion of some of these things that are happening on most of the generic key strokes. Pagination for us is the blue selected box. After it creates the tr, it calls view.dispatch(tr); Pretty typical, but, profiling reveals all of this. Most of which Isn’t code that I understand or understand what is going on enough to improve the performance of typing.