Case: Custom element used as visual page break element in the editor. The element needs to be an inline element. It will be shown as block in the editor, but should be inserted as inline element inside the content. Similar (and perhaps better as inline example) is a visual tab character. (green bar is active paragraph in editor)
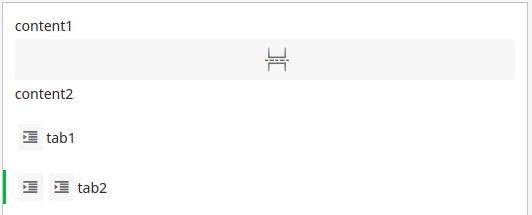
Current:
By ProseMirror inside a <p> element the custom inline element is added as expected.
<p>content1<pagebreak></pagebreak>content2</p>
When the content is saved, the XMLDocument is serialized using new XMLSerializer().serializeToString(content); to
<p>content1<pagebreak/>content2</p>
which is still fine XML.
Problem:
When this content is passed back to the editor to be parsed by the schema/ Dom parser, the self-closed element is “eating” the content right after it:
<p>
content1
<pagebreak>content2</pagebreak>
</p>
The schema:
// NOTE: although the id and data-id are handled in this schema but not in the example,
// I've tested both with and without this extra functionality.
export const pageBreak: NodeSpec = {
attrs: {
id: {default: null}
},
inline: true,
content: "inline*",
group: "inline",
atom: true,
parseDOM: [
{
tag: "pagebreak",
getAttrs(dom) {
let attrs = {};
if (dom instanceof HTMLElement) {
attrs["id"] = dom.getAttribute("data-id");
}
return attrs;
}
},
],
toDOM(node) {
return ["pagebreak", {"data-id": node.attrs["id"]}];
}
};
- Is it possible to use this kind of empty elements in ProseMirror?
- What is the reason the empty element “eats” the text right after the custom element? It’s just like it does not allow this element to be empty, so use the next content untill a well-known element (like textnode or
</p>) is encountered.
Extreme example
Exported content
<p>content1<pagebreak></pagebreak><pagebreak></pagebreak><pagebreak></pagebreak>content2</p>
Is parsed into the editor as
<p>
content1
<pagebreak>
<pagebreak>
<pagebreak>
content2
</pagebreak>
</pagebreak>
</pagebreak>
</p>
