I’ve written a small tool for searching nodes and some simple manipulations like appending text or deleting nodes, mainly for
the purpose of learning.
The util can be used as follows:
// Delete all text nodes contained in blockquotes
$node(doc).find('blockquote').find('text').delete(view);
// Append text to text nodes within blockquotes
$node(doc).find('blockquote').find('text').contains('some text').append('some other text');
// Search for blocks filtered by a custom filter
$node(doc).find().block().where(customFilter);
The query result contains a flat and a tree view of the resulting nodes with position information.
The tree can be helpful for example when deleting nodes, so we only have to delete the root nodes.
For me this is mainly a small project in order to get used to indexes and positions etc. but I was wondering if such a tool already exists and if such a tool would even be helpful when dealing with everyday editor issues.
It just uses textContent of a node and checks for indexOf, nothing complex. I did not really want to present this tool or its features, it should rather serve as an example. Currently it’s probably not that bulletproof, since I did not test all filters etc.
My question is rather which kind of queries or manipulation could be simplified with such a tool and are common when solving editor issues.
So this topic was rather meant for discussion to assamble ideas etc, but it seems not to be that interesting
I think its a good idea to keep the core clean, without too much convenience functions, but I think a tool like this as seperate module could increase the productivity especially for beginners.
Nonetheless, for now I’ll add my own usecases to the tool, would be great if there will be an “official” module for this in the future.
I only asked because we have a find and replace tool for an editor and I realized that we insert widthless notes that are not meant to be decorations.
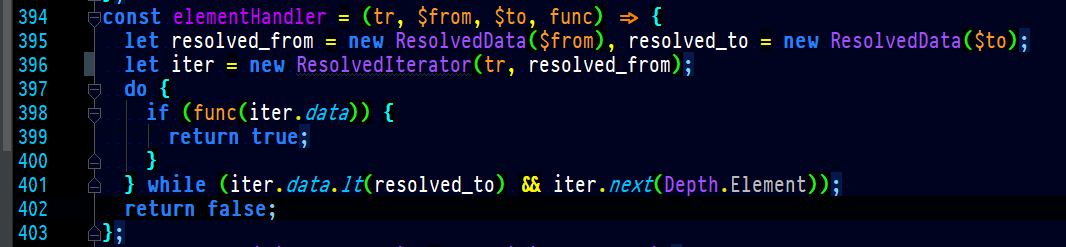
We have a similar tool that traverses the prosemirror model starting at a resolvedpos. I added in all kinds of support for doing stuff relating to tree depth comparison. I use it to traverse nodes or go across our page breaks and so on. iter.next and iter.prev take an enum value it’s basically depth, in this case Elements is 2, Pages is 1 etc. It’s completely generic, it could be any depth, it’ll find whatever is next at whatever depth. It does not use tr.doc.resolve, it uses the information you can retrieve from a resolvedpos to traverse the whole document. Here is what it looks like to scan all the nodes within a range at a specific depth.
I couldn’t share the code even if I wanted to however, but, I can sorta share the idea of using resolvedpos. I can confirm to you that it is far faster to not use resolvedpos when possible. Even if you have use a lot of variables to go between nodes or create classes etc. Its substantially faster. Might be less obvious to some people to do this. Recursion is key.
His code can help you, probably. The only thing i can do is give you hints. The iterator class I use, uses recursion to “increment or decrement” to the next node at the lowest depth until it can’t expand to the desired depth. And my iterator uses this to implement a lambda function for finding nodes at only specific depths because like I said, we use paged content, so it makes sense for us. But the purpose of my iterator is for pagination, mostly. I also use it to rejoin elements, for all kinds of keystroke functionality, etc. Its very useful for keystroke functionality because you can just get the resolvedpos for free from the selection.
You pretty much have to come up with your own ways of accessing and traversing his nodes easier because it creates a lot of noise in the source code trying to do stuff. Not to mention the readability of that sort of code is pretty low. The higher level implementation of traversal helps make this a whole lot easier in my opinion.
Unfortunately, the developer has to make up for a lot of the missing functionality, It’s not a bad thing. Helps if you have a university degree and paid attention in algorithms class, Or you know how to write some recursive functions.
 I think its a good idea to keep the core clean, without too much convenience functions, but I think a tool like this as seperate module could increase the productivity especially for beginners.
I think its a good idea to keep the core clean, without too much convenience functions, but I think a tool like this as seperate module could increase the productivity especially for beginners.