the thing is that I got the properties/attributes too for a ton of other stuff in a non-modal window (I got observers so changing them will change the rendering too) - but i’d really like some of it to be content editable in the normal “flow”… that also means that I’ll need to extend the parser - not rewrite it as my schema will sit on top of exiting.
a few question here:
- in from_dom.js @ addElement it goes
if (rule && rule.skip.nodeType) dom = rule.skip- when does bool skip becomes an element? a wee bit hard for me to read non-typescript code - a bit of a guessing game. - the order of the nodes seems to matter when using “content” in the schema - see sample below.
- should the from_dom not use the group? see P bellow - it gets a match even though its another group.
schema extending the basic:
doc: { content: "(block|x_grp)+ " },
"x_object": <NodeSpec> {
group: "x_grp",
content: "x_dummy",
toDOM: (node: Node) => ["div", { class: "x-object" }, 0],
parseDOM: [{ tag: "object", }]
},
"x_dummy": <NodeSpec> {
group: "x_grp",
content: "x_child_1 x_child_2",
toDOM: (node: Node) => ["div", { class: "x-dummy" }, ["b", "Stuff"], ["span", 0] ],
parseDOM: [{ tag: "dummy", skip: true }]
},
"x_child_1": <NodeSpec> {
group: "x_grp",
content: "inline*",
toDOM: (node: Node) => ["div", { class: "x-child-1" }, 0],
parseDOM: [{ tag: "child-1", }]
},
"x_child_2": <NodeSpec> {
group: "x_grp",
content: "inline*",
toDOM: (node: Node) => ["div", { class: "x-child-2" }, 0],
parseDOM: [{ tag: "child-2", }]
},
then this (order - child 2 then 1 does not compute):
<object>
<p>whUt?</p>
<child-2>Ok 2</child-2>
<child-1>Ok 1</child-1>
</object>
becomes:
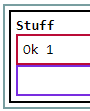
and this (bad match? P becomes a part of the group etc.):
<object>
<child-1>Ok 1</child-1>
<p>whUt?</p>
<child-2>Ok 2</child-2>
</object>
becomes:
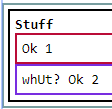
it seems like its very close to being able to handle all this - theres just a few caveats - or logic that I don’t get.