This essay about Syntax Directed Editing by Laurence Tratt bubbled up on hackernews recently.
I had not heard specifically of SDEs before (although I had read some papers about JetBrains MSP and some of their R&D around abstract-syntax-tree driven editors), so I found the example Laurence provides about how his Eco editor uses grammars to define how polyglot code blocks can and cannot be composed together in the editor to be at least superficially similar to prosemirror’s schema + node architecture.
Below are a couple excerpts from the essay. Note how, like prosemirror,
-
the editor depends on a predefined grammar defining what nodes are valid in the document
-
the document cannot be serialized to plain text / ascii without loosing information, so instead the source code is serialized as compressed json.
I’m curious to know if prosemirror contributors have heard of SDEs before or if the architectural similarities are more the product of convergent evolution (or convergent design).
https://tratt.net/laurie/blog/entries/an_editor_for_composed_programs.html
[in our prototype editor Eco,] we have taken a pre-existing incremental parsing algorithm and extended it such that one can arbitrarily insert language boxes at any point in a file. Language boxes allow users to use different language’s syntaxes within a single file. This simple technique gives us huge power. Before describing it in more detail, it’s easiest to imagine what using Eco feels like.
Imagine we have three modular language definitions: HTML, Python, and SQL. For each we have, at a minimum, a grammar. These modular languages can be composed in arbitrary ways, but let’s choose some specific rules to make a composed language called
HTML+Python+SQL: the outer language box must be HTML; in the outer HTML language box, Python language boxes can be inserted wherever HTML elements are valid (i.e. not inside HTML tags); SQL language boxes can be inserted anywhere a Python statement is valid; and HTML language boxes can be inserted anywhere a Python statement is valid (but one can not nest Python inside such an inner HTML language box). Each language uses our incremental parser-based editor. An example of using Eco can be seen in Figure 1.
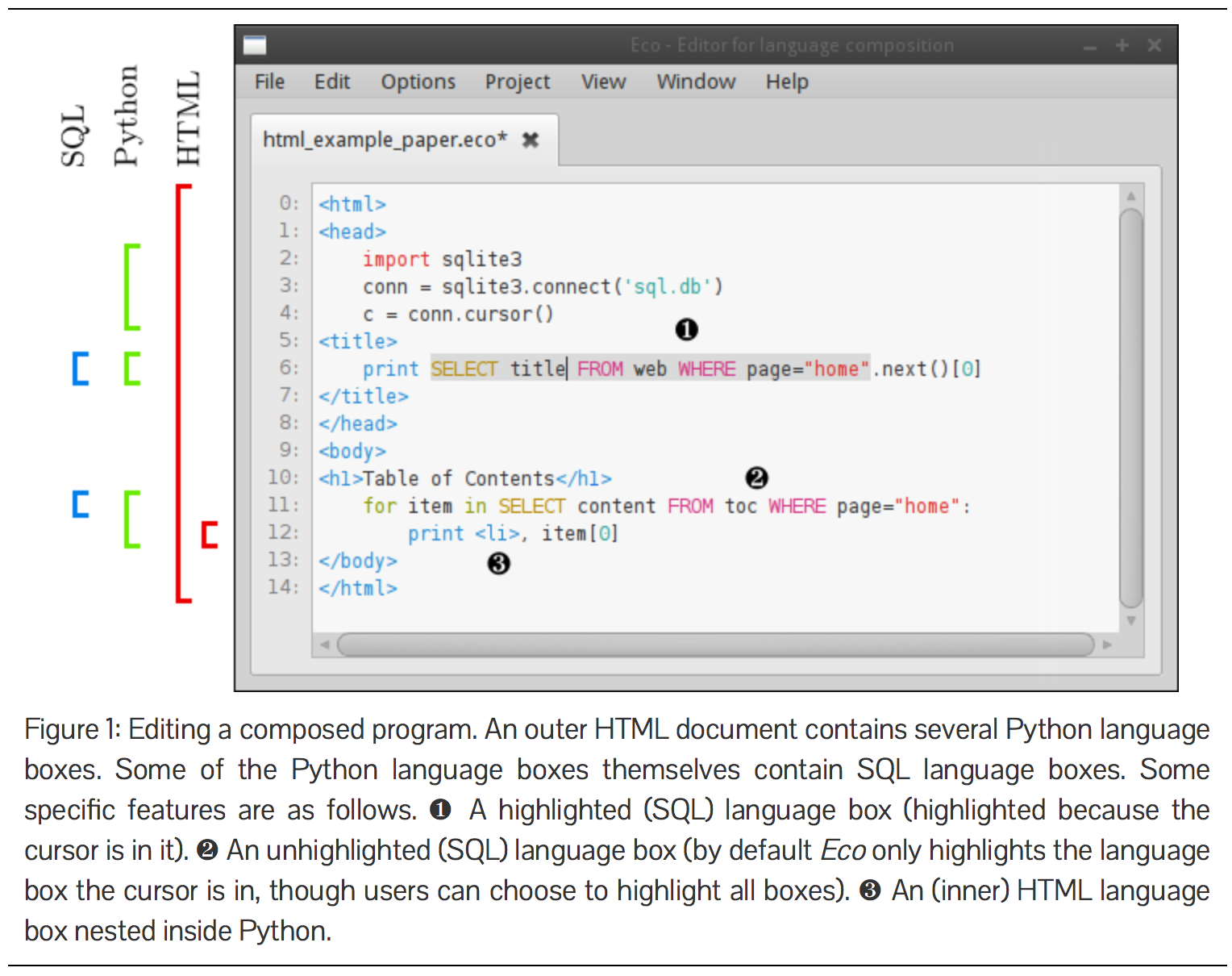
…
Consequences
Since, in general, one cannot guarantee to be able to parse as normal text the programs that Eco can write, Eco’s native save format is as a tree [4]. This does mean that one loses the traditional file-based notion of most programming languages. Fortunately, other communities such as Smalltalk have long since worked out how to deal with important day-to-day functionality like version control when one moves away from greppable, diffable, files. We have not yet incorporated any such work, but it seems unlikely to be a hugely difficult task to do so.
If you’re interested in finding out more about Eco , you can read the (academic) SLE paper this blog post is partly based on, or download Eco yourself [5]. The paper explains a number of Eco 's additional features—it has a few tricks up its sleeves that you might not expect from just reading this blog.
ref footnote [4] It currently happens to be gziped JSON, which is an incidental detail, rather than an attempt to appeal to old farts like me (with gzip) as well as the (JSON-loving) kids. [5] Depending on when you read this, you may wish to check out the git repository, in order to have the latest fixes included.