I’m working with a schema in which the doc can only contain “row” nodes (in schema: content: 'rownode*', and each rowNode must contain precisely nodes “left” “mid” and “right” (in schema: content: 'leftnode midnode rightnode')
So a resulting document might look like this:
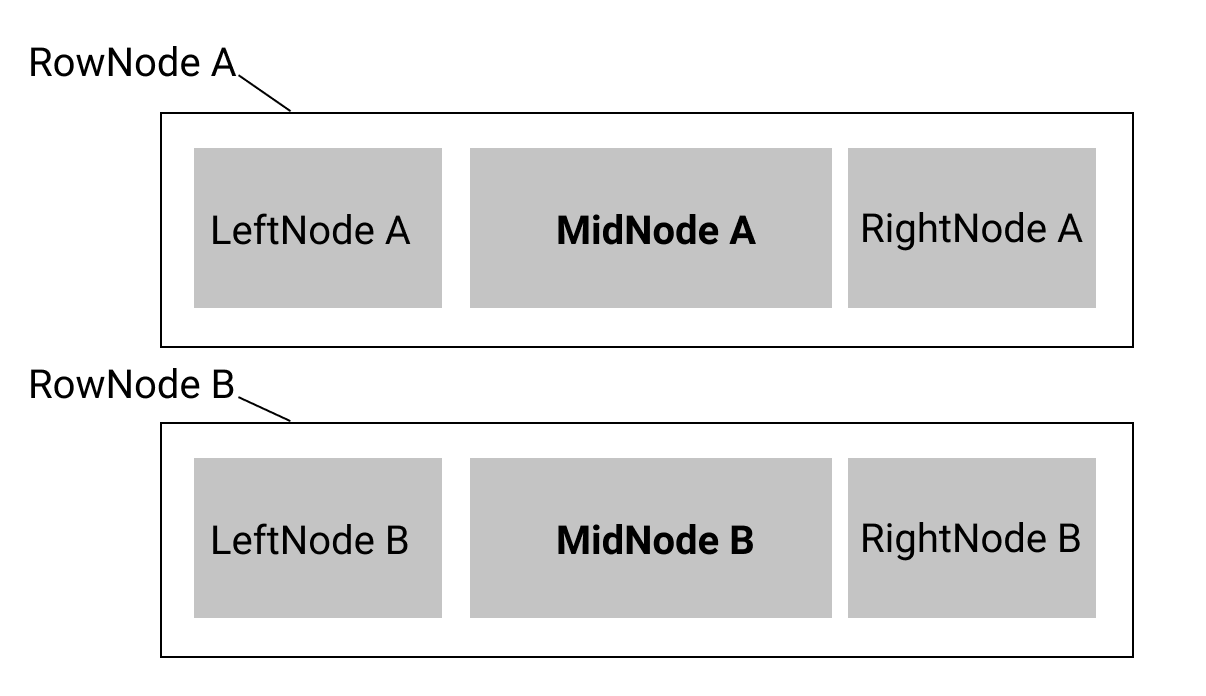
This rigid structure of container nodes seems to lend itself to working with content in a “tree-like” fashion, whereas working with the nodes illustrated above, the contents of MidNode - which can be a more flexible variety of nodes dealing with text and the like - seems to lend itself to a “flat” structure.
I’d had in mind this sentence from the guide which I interpreted to mean that ProseMirror is flexible in working with both of these approaches:
ProseMirror nodes support two types of indexing—they can be treated as trees, using offsets into individual nodes, or they can be treated as a flat sequence of tokens.
However, when I try to work with nodes in a tree-like manner, it feels like I’m “fighting against the API” to make it do what I want.
Specifically, I do find it pretty easy to traverse to a node in the object hierarchy and get the most types of information I want from it. But then if I want to apply transforms to that node’s content, that requires a (“flat-style”) pos, and that seems like something the tree-like object’s interface makes, perhaps intentionally, difficult to obtain.
This sense that I might be “fighting against the API” compounded by statements on the forum I read which seem to advise against working with it in this way:
So I’m a bit confused as to the fundamentals of what the tree-like structure should and shouldn’t be used for - particularly in the case of examples like the diagram above that enforce a hierarchical structure by way of the schema.
The specific task I’m trying to complete is:
If the cursor is at the very beginning of MidNode B, and the user hits “backspace,” I want it to move the remaining content in MidNode B (if any) to the end of MidNode A, and then delete the entire RowNode B and its contents.
I figured I’d approach this by creating a new command that checks for appropriate conditions to do this move/delete, and then dispatches the transform, and then I’d add the command to the backspace key mapping chain of commands.
To “check for appropriate conditions” is pretty easy- the “tree” aspect being that I can “find” MidNode A if it exists by way of the tree from a ResolvedPos in MidNode B. But when it comes to actually go ahead and put the data there, it seems very difficult, since I’ve traversed by tree and now need a pos. Between the difficulty and the forum comments I highlighted above, it has me wondering if there’s another way I should be going about this.
Is there a proper way to get the node positions I need to do the transform I’m describing? Or is there another way I should be approaching this task?