I am trying to create an editor that can handle footnotes. Like described in this thread I edited my schema to allow footnotes with paragraphs within them:
footnote: {
group: "inline",
content: "paragraph+",
inline: true,
// This makes the view treat the node as a leaf, even though it
// technically has content
atom: true,
toDOM: () => ["footnote", 0],
parseDOM: [{tag: "footnote"}]
}
By including keymap(baseKeymap) as a plugin within my node view, along with 'Mod-i': toggleMark(schema.marks.em), I am able to input multiple paragraphs and italicized text within the content of a footnote. So far, so good.
However, when trying to copy paste text containing footnotes the content is not preserved within the footnote content, but pasted into the main document, like this:
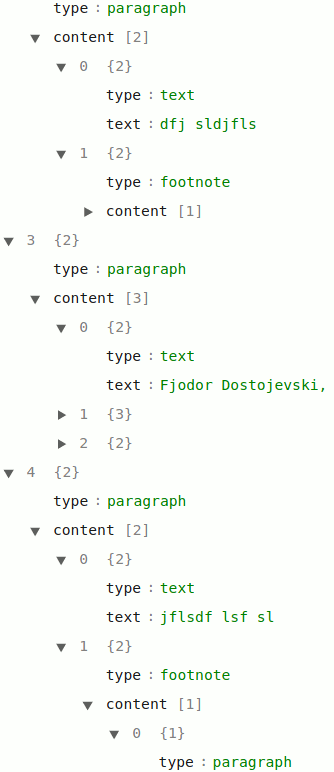
When looking at the JSON structure of my document I can clearly see a footnote containing an empty paragraph at the end of the paragraph preceding the paragraph with the footnote’s content, which is now within the main contents. Also note the extra footnote that gets inserted at the end of the pasted content (also merely containing an empty paragraph):
I think the parseDOM method needs to be adjusted. However, everything seemed to be okay in the footnote example, where footnotes also can contain content, but only inline content (content: "inline*").
For the record, I also created an example at https://glitch.com/~sandy-lamb. If I’m not mistaken the example is almost the same as the footnote example on the site, except for a formatting change (showing an asterisk instead of a footnote number) and of course changing inline* content to paragraph+. This means that of course you can’t create multiple paragraphs using enter, nor italicize text, but it also exhibits the same issue.
Ah, I see what is going on now. HTML is specified to automatically close tags like <p> when it sees another <p>. So ProseMirror serialized the copied code something like
I did some experiments with using an XML parser for clipboard data, which won’t have this issue, however that also goes wrong—it’ll get confused by things like <img> tags or messy HTML parsed from elsewhere.
So it seems that ‘use semantic HTML’ has limits—the parser’s behavior for some semantic tags makes it impossible to have some, otherwise reasonable, structures. The only way forward for you that I can think of is to move to meaningless, non-standard tags for your block nodes (say, <paragraph> instead of <p>) to sidestep this parser behavior.
Of course! And that’s also why the extra footnote appears: the browser encounters a </footnote> and inserts an opening tag before it.
I do not completely understand this issue. Which parser did you try? I assume you also fed it an xsd or dtd file? You mean <img> tags within footnotes?
That’s a reasonable workaround, as those non-standard tags only appear in the editor, the resulting internal JSON structure (and everything I can do with it) stays the same. I only had to explicitly style it as a block element, like
paragraph {
display: block;
}
to be able to divide one paragraph into two using Enter or pasting multiple paragraphs.
I wouldn’t be able to paste (multiple) paragraphs from outside of the editor (because of the parseDOM property looking for a paragraph element, instead of a p), e.g., from a Word document or just another (properly formatted) HTML page, but this is not the case: everything works like it formerly did.
Thanks for this analysis of my issue and suggesting a solution!
Just the browser’s built-in DOMParser. Tags like <img> in HTML don’t have a closing tag (nor a /> ending), and thus aren’t valid XML.
You can (and should) specify multiple parseDOM rules for your elements—that it works right now is mostly accident, and if you have multiple types of block nodes it’ll stop working.