I’m working on making a replacement for our old CKE4 implementation with a new ProseMirror implementation, and need to be careful about avoiding unintended data loss when migrating over to the new ProseMirror-based editor, as we will have old existing HTML to read from the database and must be able to survive a roundtrip through the ProseMirror implementation.
The main idea we have is that have a catch-all node for unknown content, that is simply atomic and and saves the outerHTML as an attribute, renders it as a node view and restores it back when serializing to DOM.
That part is no issue, the issue comes when I need to split the case into two due to block and inline not being allowed to be mixed in the content of a node in schema. This leads to having both unknown_inline and unknown_block with tag: *. And here is where I’m facing issue in how to properly separate these two cases consistently without triggering the automatic node wrapping or closing the parent node.
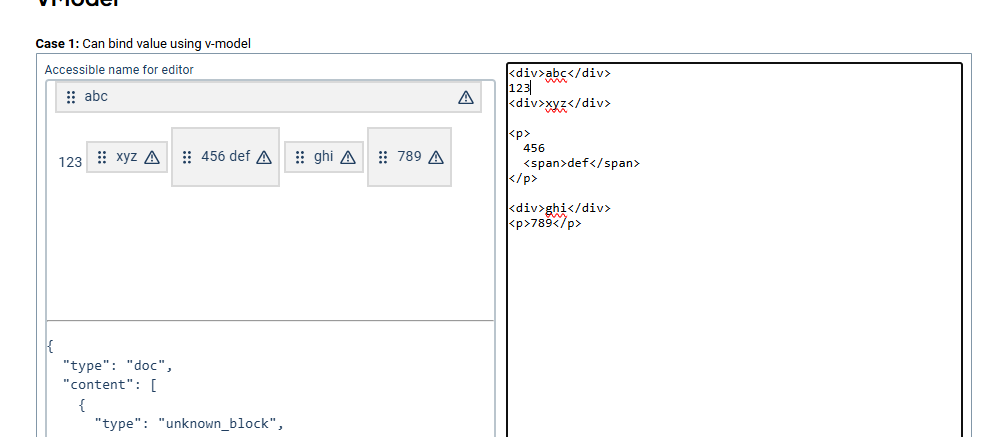
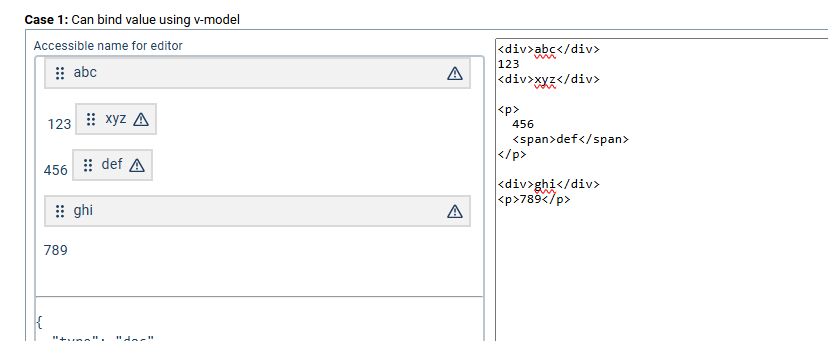
I’ve looked into using context: 'doc/' for unknown_block to ensure it only triggers at root level, but that fails during automatic node wrapping as there can be an open paragraph node generated from unwrapped text before. For example this case I can’t get to parse consistently using context: 'doc/' only:
<div>abc</div>
123
<div>xyz</div>
The second div gets ignored as 123 starts a new open paragraph for wrapping and thus the second div then fails the context check.
I’ve tried using getAttrs as a filter to check the parentElement for a class marker added to the root container that is being passed to the DOMParser. That works fine when I control how the parsing is handled, but I don’t know how that scales for pasting and other functionality that parses by themselves, so that the marker is not guaranteed to exist in all cases.
Another approach is that I’ve tried tag: 'p *' as a selector for the unknown_inline, but that only works if i can be sure about the ancestors. I don’t know if copy and pasting from outer sources might include a weird P tag at root level and thus making all unknown content into unknown_inline.
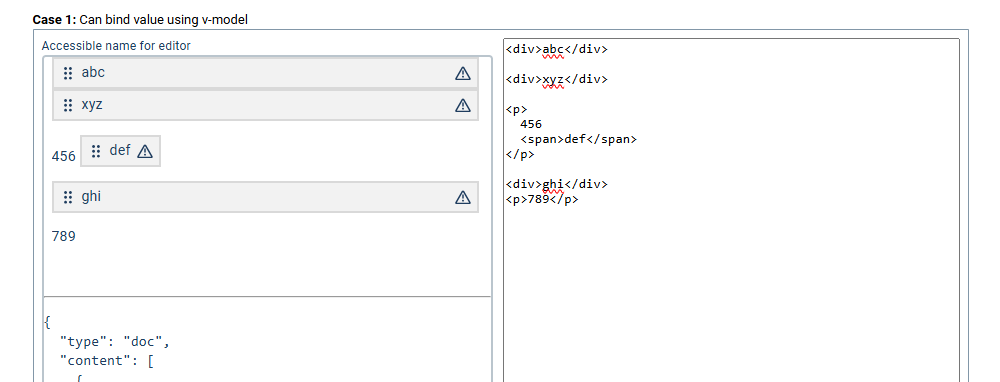
So what approaches would be best for us in order to best preserve the structure of unknown HTML content? Here is basic test case I have for when only paragraphs and text is defined as known nodes in the schema, everything else should be preserved as is and parsed as unknown nodes, including not changing the ancestors of the unknown content:
<div>abc</div>
123
<div>xyz</div>
<p>
456
<span>def</span>
</p>
<div>ghi</div>
<p>789</p>