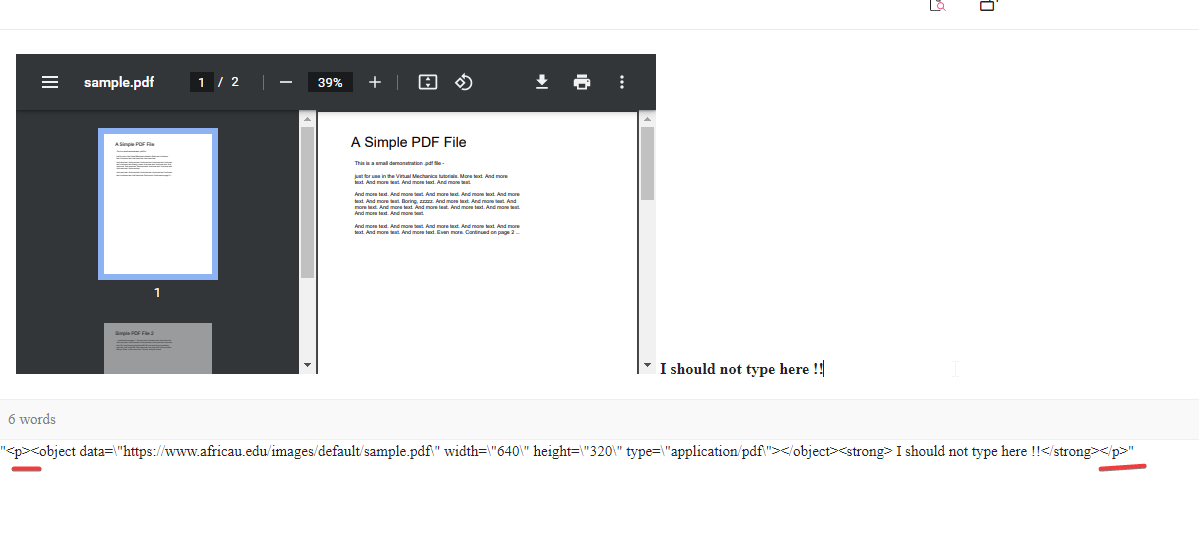
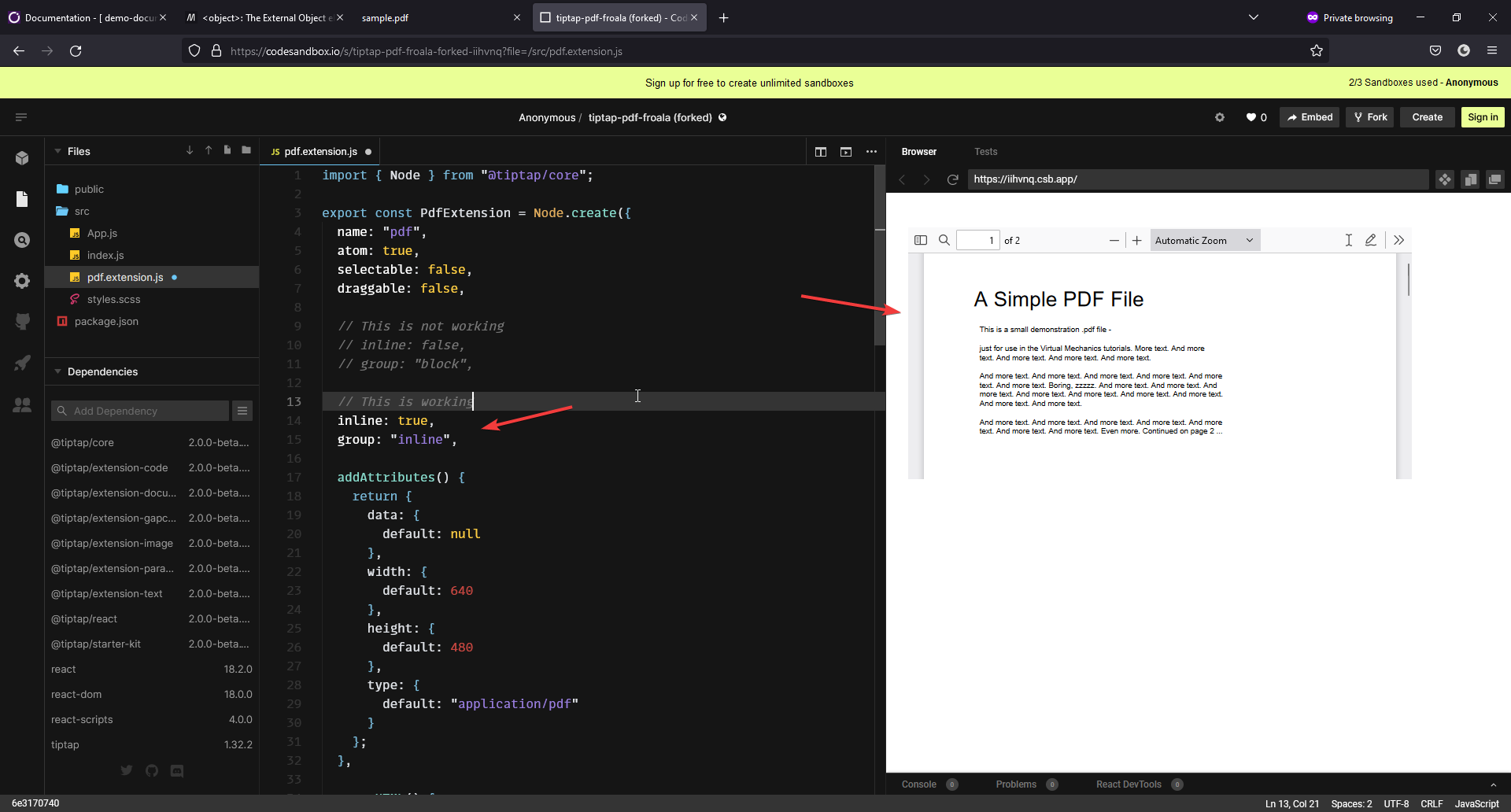
Once again, I thank you for your response, I think I might have got it working. I am just summarizing my understanding to just double check if I am doing it right & will also help other people who come searching similar query in future.
- Since my existing HTML output from
froala has the PDF 1 level inside the <p> tag, & I want it to be treated as block node in ProseMirror
- I extended the
Paragraph extension to check whether the first child of the <p> tag is a PDF using the parseHTML() rule
- I also added an attribute called
isPdf in the extension to output renderHTML() / toDom() conditionally
parseHTML() {
const getPdfAttribuesFromFroalaHTML = (element: HTMLElement): ParsedElementResult | boolean => {
// Your logic to find if the node is a valid PDF document
const result = {
height: height,
data: src,
width: width,
isPdf: isPdf,
};
return result;
}
return false;
};
return [
{
tag: "p",
getAttrs: (element) => {
if (typeof element === "string") return {};
return getPdfAttribuesFromFroalaHTML(element);
},
},
];
},
Now after parsing it successfully in order to render it
renderHTML({ HTMLAttributes }) {
const isPdf = HTMLAttributes.isPdf;
if (isPdf) {
return ["object", { ...HTMLAttributes }];
}
return ["p", mergeAttributes(this.options.HTMLAttributes, HTMLAttributes), 0];
},
Since the above output is rendering an object tag to hold the pdf which will be my new PDFExtension to handle further renders.
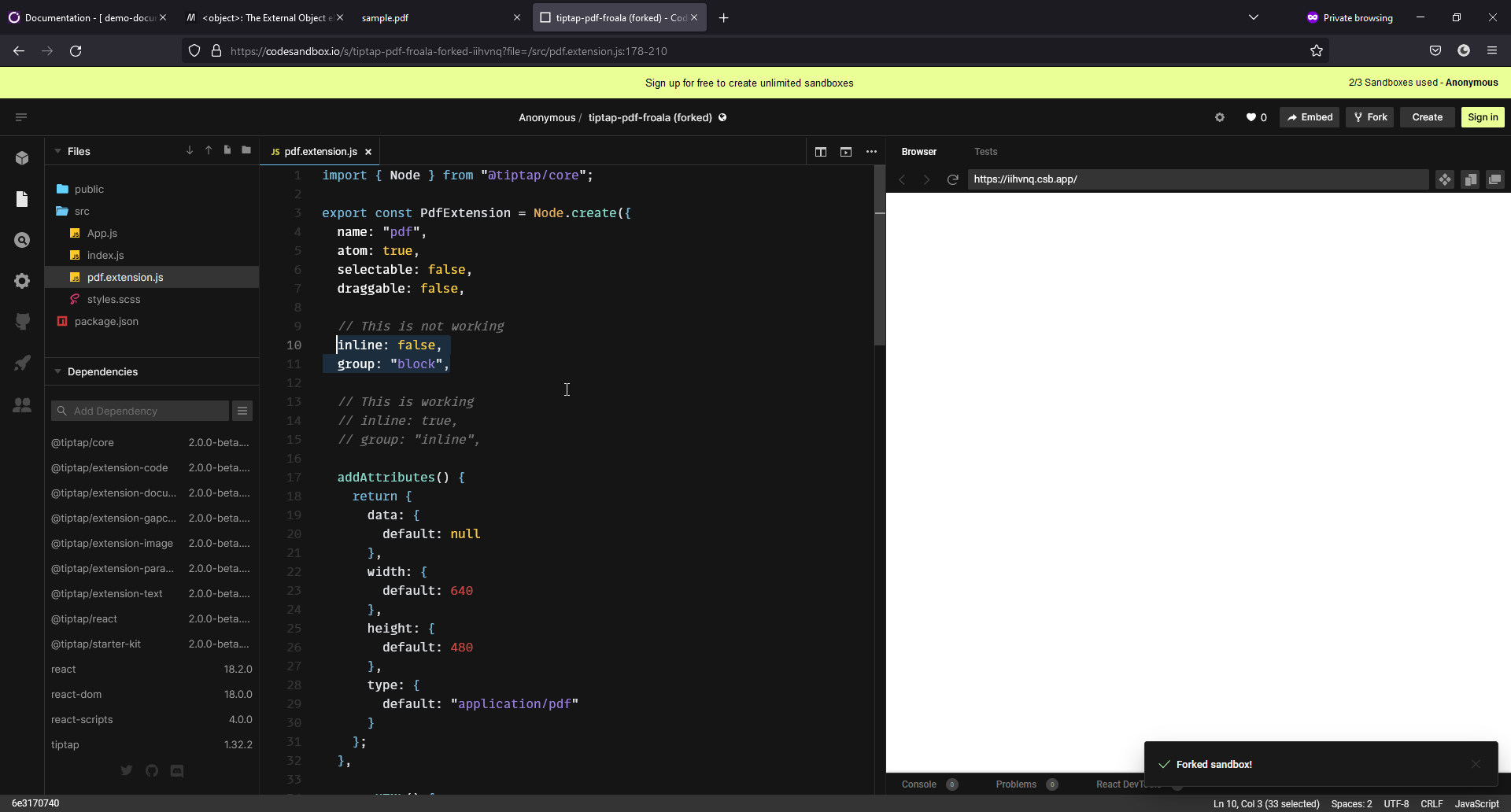
export const PdfExtension = Node.create({
name: "pdf",
atom: true,
selectable: false,
draggable: false,
inline: false,
group: "block",
addAttributes() {
return {
data: {
default: null,
},
width: {
default: DEFAULT_ELEMENT_WIDTH,
},
height: {
default: DEFAULT_ELEMENT_HEIGHT,
},
type: {
default: "application/pdf",
},
};
},
parseHTML() {
return [
{
tag: "object",
},
];
},
renderHTML({ HTMLAttributes }) {
return ["object", { ...HTMLAttributes }];
},
});
Please modify/suggest any improvements if any.