Hello Prosemirror, first of all such an elaborate and incredibly powerful library this is. I wanted to ask specifically about a use-case we’re trying to solve. Our team currently supports rich text for web pages, and the goal is to add support for apps as well. One of the caveats is around special characters (zero-width space, non-breaking space and line separator). Specifically, we want to save these as unicode instead of HTML entities in our payload.
Here’s an example of some content with special characters in it.
{
"type": "doc",
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": "h ello world, h ow you been?"
}
]
},
{
"type": "paragraph"
},
{
"type": "paragraph",
"content": [
{
"type": "text",
"marks": [
{
"type": "strong"
}
],
"text": "Good"
},
{
"type": "text",
"text": " to "
},
{
"type": "text",
"marks": [
{
"type": "em"
}
],
"text": "see"
},
{
"type": "text",
"text": " "
},
{
"type": "text",
"marks": [
{
"type": "em"
},
{
"type": "strong"
}
],
"text": "you"
},
{
"type": "text",
"text": " my old friend"
}
]
},
{
"type": "bullet_list",
"content": [
{
"type": "list_item",
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": "this is a list"
}
]
}
]
},
{
"type": "list_item",
"content": [
{
"type": "paragraph",
"content": [
{
"type": "text",
"text": "this is also a list "
}
]
}
]
}
]
}
]
}
This works great (when converted back into html and it recognizes the special characters).
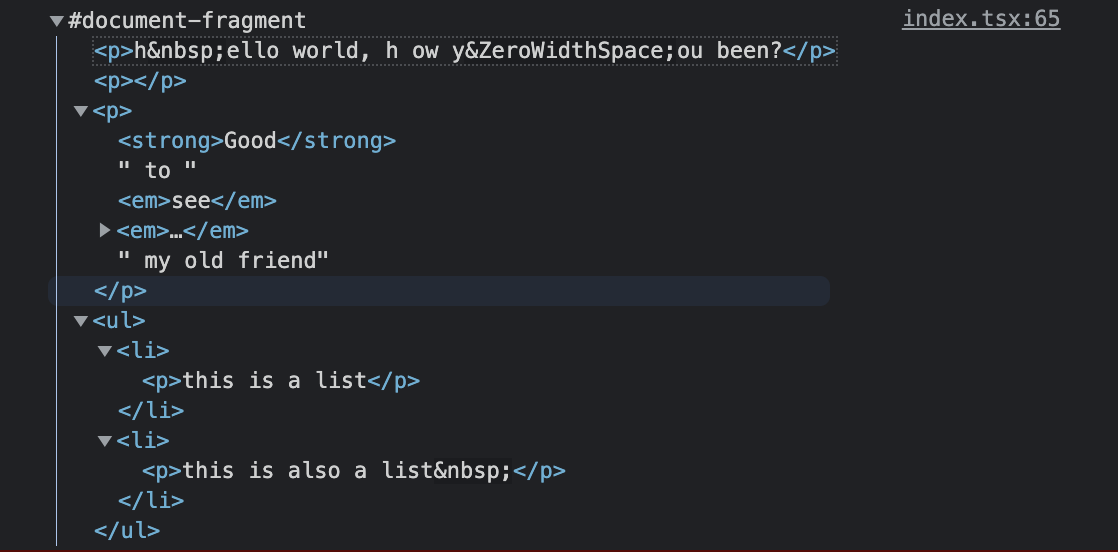
but I am looking for ideas around how else can these special characters be stored for greater flexibility.
Thank you!